

It should come as no surprise that the marketing industry is riding a wave of change. In the wake of prolific data breaches and prominent scandals, consumers are demanding better protection of their personal information. In response, lawmakers are listening, introducing expansive data privacy regulations. Marketers have had to re-assess the way we collect, disseminate, and store sensitive information—learning to put privacy at the forefront and leaving behind the insecure and invasive methods of yesteryears.
For now, the search is on for privacy-preserving solutions to be deployed at scale that will get marketers the data they need without infringing on the rights of users. As of late, thrown into the discussion are the terms “differential privacy” and “federated learning”—and if you haven’t heard of them yet, you probably will. Apple has been using differential privacy techniques since 2017, also combining it with federated learning as of iOS 13. Meanwhile, Google has released an open-source version of its differential privacy library to the world.

So, what are they?
These concepts might seem like nothing more than just obscure technological jargon, but they’re becoming increasingly relevant to the workings of today’s marketing industry. With that in mind, we thought it would be pertinent to start off our blog series by explaining the ins and outs of these two concepts and how they just might shape the way we collect, analyse, and store data in the years to come.
How does differential privacy work?

Pioneered by Microsoft, differential privacy is a statistical technique that allows companies to collect and share aggregate data about user habits while protecting the privacy of individual users. Several big tech companies—like the aforementioned Apple and Google—are already using differential privacy in some capacity, and will probably look to leverage this technique more widely as they move away from cookie-based tracking and other invasive data collection techniques.
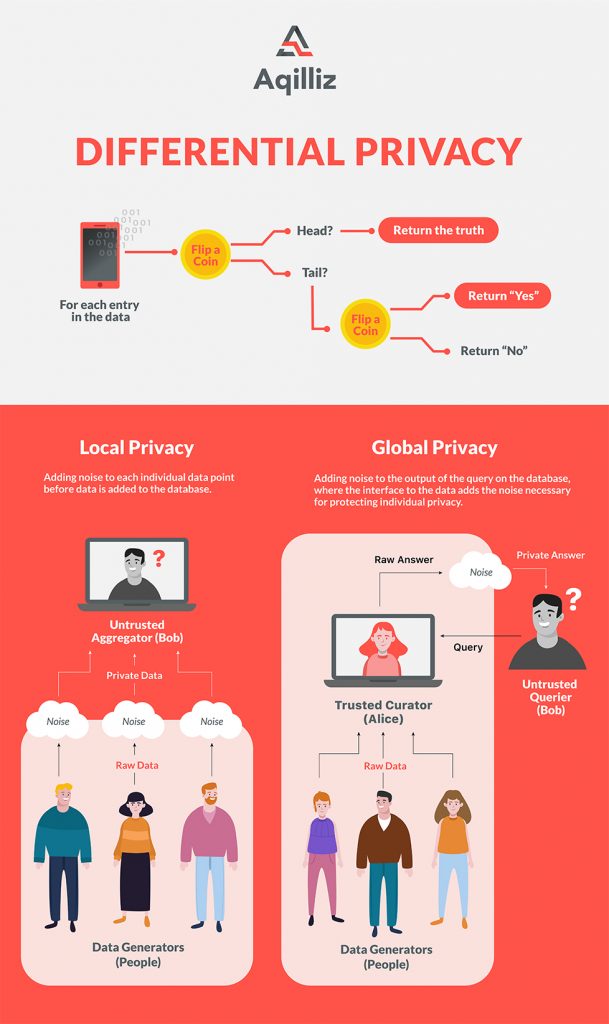
Briefly, a differential privacy algorithm inserts random data into an original data set at the collection stage to mask individual data points before they are further anonymised on a server. Advertisers then get approximate data sets that they can use to answer questions without compromising anyone’s privacy.
Why is it useful?
The goal here is to prevent the reverse engineering of specific data points to identify people, or at least to introduce plausible deniability for users because no data point can be tied to a person with complete certainty. It is evident that current practices of anonymising data are falling short of the mark, as identity can be inferred from behavioural patterns and openly shared parcels of information such as gender, postcode, or even date of birth. Introducing noise to raw data adds another layer of protection to prevent any one person’s information from being distinguished or re-identified.
Undoubtedly the future for marketers is a balancing act of keeping personal identities secure while obtaining accurate and useful data to understand how people are responding to a campaign. This is where differential privacy has a role to play in helping the marketing industry achieve regulatory compliance. However, this technique cannot be applied to small data sets where the added noise could make the inferred information largely inaccurate—differential privacy works best on large collections of data, but it’s difficult to employ at scale unless other methods such as federated learning are incorporated.
So what exactly is federated learning?
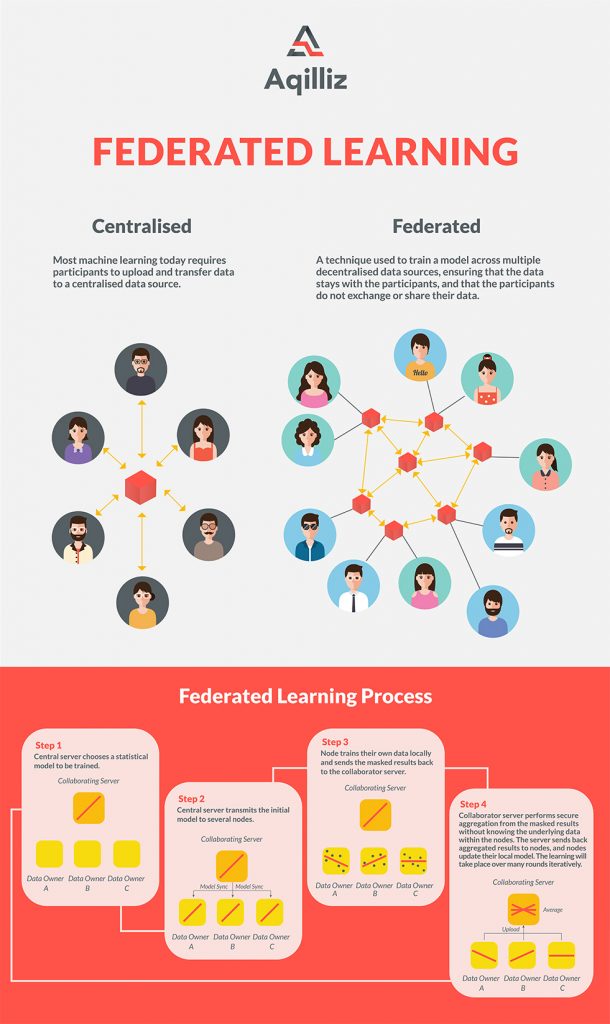
Federated learning presents a step away from current centralised data aggregation models, ushering in a new era of decentralisation for the marketing industry. In present-day systems, data is sent to a centralised server to be analysed and stored while relevant information is used to alter algorithms and improve models. Centralisation necessitates a constant, increasing demand for data storage capacity, and data is vulnerable to security breaches when being transferred or stored.
Federated learning instead allows for machine learning through decentralisation. It’s a solution that enhances user privacy because personal data always remains in local storage, never leaving the devices from which it originates. How federated learning works is that a model is pushed out to devices with user permission—allowing algorithms to train themselves directly on the device and only sending back relevant data summaries to the central server. Differential privacy techniques can be applied to mask personal information before it is sent by encrypted communication to the cloud, where it is then averaged with other user updates to further mask individual data points.
And what does this all mean?
When blockchain is thrown into the mix, what you have is a perfectly privacy compliant model for data collection, aggregation, and analysis, with assurances that all data points introduced into the system are authentic and verifiably true. The triad of these three promising technologies is in fact what forms our solution, Neutron, a distributed data management platform that securely aggregates high quality first-party data from participating brands. With such technologies, marketers can continue to leverage user data to deliver relevant and meaningful marketing messages to sustain brand integrity and brand loyalty while remaining compliant to relevant data privacy frameworks.
However, the possible applications for federated learning and differential privacy go beyond our marketing ecosystem. Though still very much in their early days, it’ll certainly take time before we see widespread adoption of differential privacy and federated learning methods across the martech ecosystem. As the biggest names in tech bet on these techniques for their own operations, we can eventually hope to see them working within and across some of the most prolific platforms in use today. As one of the most promising solutions to mastering the delicate balance between personalisation and privacy, we’re willing to bet that these techniques will shape the global standard for compliant data collection practices as we know it today.















